
一、引言
在国内做 CodeReview 真心不容易,除了大厂外,其他的从上到下很少人会重视,当然也有一些带头大哥会去推进 CodeReview,做一些力所能及的事情。浏览了众多文档,觉得有篇写的相当不错,因此在原文的基础上,做了一些调整。
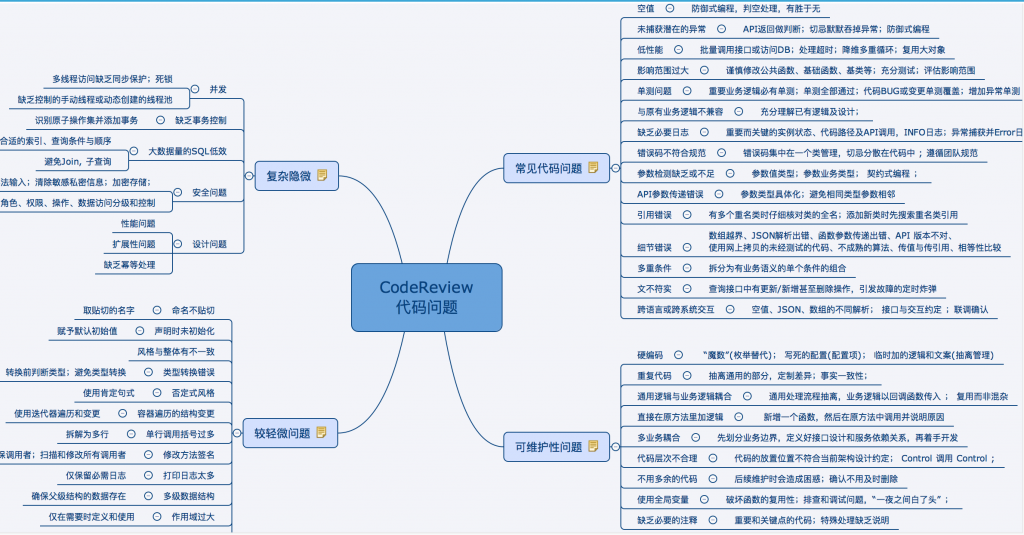
二、常见代码问题
常见的潜在代码问题是直接会导致闪退、死机、故障或者产品功能不能正常工作的类别。
2.1 空值
空值恐怕是最容易出现的地方之一。 常见错误有:
- 值为 NULL(变量未初始化)导致空指针异常
- 参数字符串含有前导或后缀空格没有 Trim 导致查询为空
原则上,对于任何异常, 希望能够打印出具体的错误信息,根据错误信息很快明白是什么原因, 而不是一个 null ,还要在代码里去推敲为什么为空。这样我们必须识别出程序中可能的null, 并及时检测、捕获和抛出异常。
对于空值,最好的防护是“防御式编程”。当获取到对象之后, 使用之前总是判断是否为空,并适当抛出异常、打错误日志或做其它处理。
2.2 未捕获潜在的异常
调用API接口、库函数或系统服务等,只顾着享受便利却不做防护,常导致因为局部失败而影响整体的功能。最好的防护依然是“防御式编程”。 要么在当前方法捕获异常并返回合适的空值或空对象,要么抛给高层处理。
切不可默默"吞掉错误和异常"。 分析问题的时候一定要仔细询问:这里是否可能会抛出异常?如果抛异常会怎么处理?是否会影响整体服务和返回结果?
2.3 影响范围过大
对多个模块依赖的公共函数的修改,容易造成影响范围超过当前业务改动,无意识地破坏依赖于该公共函数的其他业务。要特别慎重。可靠的方式是:先查看该公共函数的调用, 如果只有自己的业务用,可适当大胆一些; 如果有多个地方依赖,抽离一个新的函数,抽离原函数里的可复用部分,然后基于可复用部分构建新的函数。修改原则遵循“开闭”原则,才能尽可能使改动影响降低到最小化。
基类及实例字段和方法也属于公共函数的范畴。 尽量不要修改基类的东西。
2.4 缺乏必要日志
对于重要而关键的实例状态、代码路径及 API 调用,应当添加适当的 Info 日志;对于异常,应当捕获并添加 Error 日志。缺乏日志并不会影响业务功能,但出现问题排查时,就会非常不方便,甚至错失极宝贵的机会(不易重现的情况尤其如此)。此外,缺乏日志也会导致可控性差,难以做数据统计和分析。
2.5 参数检测缺乏或不足
参数检测是对业务处理的第一层重要过滤。如果参数检测不足够,就会导致脏数据进入服务处理,轻则导致异常,重则插入脏数据到数据库,对后续维护都会造成很多维护成本。方法:采用“契约式编程”,规定前置条件,并使用单测进行覆盖。
对于复杂的业务应用, 优雅的参数检测处理尤为重要。 根据 “集中管理和处理一致性原则”, 可以建立一个 paramchecker 包, 设计一个可复用的微框架来对应用中所有的参数进行统一集中化检测。参数检测主要包括:
- 参数的值类型, 可以根据不同值类型做基础的检测
- 参数的业务类型, 有基础非业务参数, 基础业务参数和具体业务参数
不同的参数业务类型有不同的处理。 将参数值类型与参数业务类型结合起来, 结合一致性的异常捕获处理, 就可以实现一个可复用的参数检测框架。参数检测既可以采用普通的分支语句,也可以采用注解方式。采用注解方式更可读,不过单测编写更具技巧。
2.6 名字冲突
名字冲突常常出现在自定义函数命名跟库函数名字一样的情况下。此时,自定义函数的定义会覆盖库函数,导致在某一处正常,而其他地方出问题。因此,在命名时要足够有意识,避免和库函数命名冲突。
2.7 细节错误
比如逻辑运算符误写、优先级错误、长整型截断、溢出、数组越界、JSON 解析出错、函数参数传递出错、API 版本不对、使用网上拷贝的未经测试的代码、不成熟的算法、传值与传引用、相等性比较等。
对于数组越界错误, 通常要对空数组、针对数组大小的边界值 + 1 和 - 1 写单测来避免; 使用网上拷贝的代码,诚然可节省时间,也一定要加工一下并用单测覆盖;传值和传引用可通过单测来避免错误; 对象的相等性比较切忌使用等号 =。
2.8 文不符实
文不符实是一种可能导致线上故障的错误。比如一个 getXXX 的函数,结果里面还做了 add, update 的操作。对问题排查、产品运维等都有非常大的杀伤力。因此命名一定要用实质内容相符,除非是故意搞破坏。
三、可维护性问题
可维护性问题是指在当前业务变更的范围内通常不会导致闪退、故障,却会在日后埋下地雷,引发 Bug、故障、维护成本大幅增加的类别。
3.1 重复代码
重复代码在当前可能不会造成 Bug,但上线后,需要维护多处的事实;时间一长,后续修改的时候就特别容易遗漏或处理不一致导致 Bug;重复代码是公认的“代码坏味”,必当尽力清除。方法: 抽离通用的部分,定制差异。重复代码还有一种情况出现,即创造新函数时,先看看是否既有方法已经实现过。
3.2 多业务耦合
在业务边界未仔细划分清晰的情况下出现,一个业务过多深入和掺杂另一个非相关业务的实现细节。在项目和系统设计之初,特别要注意先划分业务边界,定义好接口设计和服务依赖关系,再着手开发;否则,延迟到后期做这些工作,很可能会导致重复的工作量,含糊复杂的交互、增加后期系统维护和问题排查的许多成本。磨刀不误砍柴工。划分清晰的业务、服务、接口边界就属于磨刀的功夫。
3.3 不用多余的代码
工程中常常会有一些不用的代码。或者是一些暂时未用到的 Util 工具或库函数,或者是由于业务变更导致已经废弃不用的代码,或者是由于一时写出后来又重写的代码。尽量清除掉不用多余的代码,对系统可维护性是一种很好的改善,同时也有利于 CodeReview。
3.4 使用全局变量
使用全局变量并没有“错”,错的是,一旦出现问题,排查和调试问题起来,真的会让人“一夜之间白了头”,耗费数个小时是轻微惩罚。此外,全局变量还能“顺手牵羊”地破坏函数的通用性,导致可维护性变差。务必消除全局变量的使用。当然,全局常量是可以的。
3.5 缺乏必要的注释
对重要和关键点的代码缺乏必要的注释,使用到的重要算法缺乏必要的引用出处,对特别的处理缺乏必要的说明。
原则上, 每个方法至少要用一个简短的单行注释, 适宜地描述了方法的用途、业务逻辑、作者及日期。对于特殊甚至奇葩的需求的特别实现,要加一些注释。 这样后续维护时有个基础。
四、难发现的错误
难发现的错误是指:复杂并发场景下的有一定技术难度的、需要丰富开发与设计经验才能看出来的错误。
4.1 并发
并发的问题更难检测、复现和调试。常见的问题有:
- 在可能由多线程并发访问的对象中含有共享变量却没有同步保护;
- 在代码中手动创建缺乏控制的线程或线程池
- 并发访问数据库时没有做任何同步措施
- 多个线程对同一对象的互斥操作没有同步保护
使用线程池、并发库、并发类、同步工具而不是线程对象、并发原语。在复杂并发场景下,还需注意多个同步对象上的锁是否按合适的顺序获得和释放以避免死锁,相应的错误处理代码是否合理。
4.2 资源泄露
资源泄露通常有以下几种情况:
- 打开文件却没有关闭
- 连接池的连接未回收
- 重复创建的脚本引用没有置空,无法被回收
- 已使用完的集合元素始终被引用,无法被回收
4.3 事务
事务方面常出现的问题是:多个紧密关联的业务操作和 SQL 语句没有事务保证。 在资金业务操作或数据强一致性要求的业务操作中,要注意使用事务,保证数据更新的一致性和完整性。
4.4 安全问题
安全问题一向是互联网产品研发中极容易被忽视、而在爆发后又极引发热议的议题。安全和隐私是用户的心理红线之一。应用、数据、资金的安全性应当仅次于产品功能的准确性和使用体验。
比如:缓冲区溢出; 恶意代码注入;权限赋予不当; 应用目录泄露等。
安全问题的 CodeReview 可参见检查点清单:信息安全 。主要是如下措施:
- 严格检查和屏蔽非法输入
- 对含敏感信息的请求加密通信
- 业务处理后消除任何敏感私密信息的任何痕迹
- 结果返回前在反序列化中清除敏感私密信息
- 敏感私密信息在数据存储设备中应当加密存储
- 应用有严格的角色、权限、操作、数据访问分级和控制
- 切忌暴露服务器的重要的安全性信息,防止服务器被攻击影响正常服务运行
4.5 设计问题
设计问题通常体现在:
- 是否有潜在的性能问题
- 是否有安全问题
- 业务变化时是否容易扩展
- 是否有遗漏的点
- 持续高负荷压力下是否会崩溃
五、较轻微的问题
较轻微问题是指:没有技术难度、通过良好习惯即可避免的问题。
较轻微问题一般不会造成负面影响的 Bug 或故障,不过建立一些好的习惯,主动使用代码检测工具,消除这些较轻微错误,也是一种修行。
5.1 命名不贴切
命名不贴切不会影响功能实现,却会误导理解或增加理解难度。
方法:找个通俗易懂而且比较贴近的名字。可以参考 JDK 的命名、通用词汇和行业词汇; 作用域小的采用短命名,作用域大的采用长命名。取名字是一种重要技能,多少父母为此愁灰了头!
5.2 声明时未初始化
声明时未初始化通常情况下都不会是问题,因为后面会进行赋值。不过,如果赋值的过程中出现异常,那么可能会返回空值,从而导致空值异常。通常,变量声明时赋予默认初始值是个好习惯。
5.3 类型转换错误
编程语言的类型系统是非常重要的。如何在不同类型之间可靠地互转,尤其是在父子类型之间相互赋值,也是一个微技能。滥用类型转换,也会导致 Bug 。
Java 中容易出现的错误是:
- 字符串转数值,字符串含有非数字部分
- JSON 字符串转对象,某个字段含有不兼容的值类型导致解析出错
- 子类型转不兼容的父类型,滋生运行时异常 ClassCastException
- 相同特质的类型不兼容。比如 Long 与 Integer 都是数值型,却不能互转。
类型转换中最容易出 Bug 的地方是非布尔类型取反,容易隐藏看不出的 Bug 甚至错误。
5.4 API 参数传递错误
如果 API 参数有多个,而且相邻参数的类型相同,那么要特别留意是否参数顺序是正确的,而不会张冠李戴。
当然,在设计 API 参数的时候,就可以仔细用更精准类型进行区分,并将相同类型的参数错开。比如 calc(int accountNo, int pay, int timestamp), 就容易传错,比较可靠的是 calc(int accountNo, Currency pay, Timestamp now) ,这样是不可能将参数传递错误的。
5.5 打印日志太多
打印过多的日志并不好。一方面遮掩真正需要的信息,导致排查耗费时间, 另一方面造成服务器空间浪费、影响性能。生产环境日志一般只开放 Info 及以上级别的日志; Debug 日志只在调试或排错的时候使用,生产环境可以禁止 Debug 日志。
5.6 分支与循环
条件与循环偶尔也会导致错误, 不过通常错误可以在发布前解决掉。
对于 if-else 嵌套条件, 需要仔细检查是否符合业务逻辑; 如果嵌套太深,是否可以使用另一种方式“解结” ; 对于 switch 语句, 大多数语言的 case 有 fall through 问题, 要注意加上 break ; 最好加上 default 的处理。
对于 for 循环, 编写合理的结束条件避免死循环; 对于循环变量的控制, 避免出现 -1 或 +1 错误, 消除越界错误; for 循环也要特别注意对空值和空容器的处理,避免抛出空值异常。可以通过单测来确保 for 循环的准确性。
5.7 残留的无用代码
残留的无用代码,会成为系统的垃圾,增加系统的理解和维护成本,需要及时清理掉。
5.8 代码与文档不一致
文档是理解代码的第一扇窗口。优秀的文档,可以极大地降低理解代码的成本。但是大多数开发者还并不习惯编写友好的文档。常常出现无文档、失效文档、误导性文档等,影响人们的理解和判断。
5.9 使用冷僻用法或奇淫巧技
使用冷僻用法或奇淫巧技会增大系统的理解成本,徒然消耗人的脑细胞。
思路可借鉴,但不宜用于生产环境中,朴实最宜。