
人工智能的简述
人工智能最早是在1956年达特茅斯会议被提出的,期间经过了早期膨胀、发展困难寒冬,三起三落,到这几年再迎来爆发,尤其是在2010年,深度学习的应用使得语音、图像和自然语言处理等技术取得了很大的进展。
人工智能,本质上是思路的的延续和创新,用数学来解决现实的缺乏明确规律、规则过于复杂的问题;是一个系统的解决方案,在很多点上做全方面的突破,而不仅仅是数学、算法上的突破。
人工智能的发展史
从工业自动化开始:蒸汽机(工业化)-》电-》计算机-》AI
人工智能是工业化进程必然之路,整个工业化一开始就是从替代人力开始的,前三次工业革命从蒸汽机、电到计算机,都是在不断替代人力,解放人力,从体力到简单重复脑力,而人工智能则进入了更高层面的智力方面的替代:
- 所有问题都是数学问题
- 一个系统工程的解决方案,不仅仅是控制算法本身,还涉及到对相关行业(电气特性)的了解和突破
智能不是机器学习或者神经网络独有的,从PID控制到我们用智能手机协助处理人类的工作,智能无处不在。而今天我们提到的人工智能,与以往的其它的智能相比,更多的是有以下的特点:
- 基于大数据的训练和学习过程
- 用来处理分类问题,本质上是分析、预测等
- 处理语言这种只有人类才具有的能力
人工智能的现状
得利于算力、算法、大数据这几年的发展,人工智能得到了大范围的应用。

计算机视觉及应用
计算机视觉主要包括了目标探测(20个对象)、目标识别(路标、车辆、行人)及行为判断(微笑、跑动及其方向、静止或移动)。
早期的计算机视觉依靠人工标注提取特征,机器学习训练,最近几年基于深度学习的CNN展现出了对传统方案碾压的能力。
- 生物识别,生物特征识别
- 物体及场景,自动驾驶
- 视频分析及文字识别(OCR)
- 图像生成(GAN生成对抗网络)
语言处理及应用
语言是人类智慧的最高峰,因为有了语言,人类文明才能传承,人类的思想才能被建立。语言本质上是人类思想的表达,所以语言从理解到生成,是人工智能的巅峰。
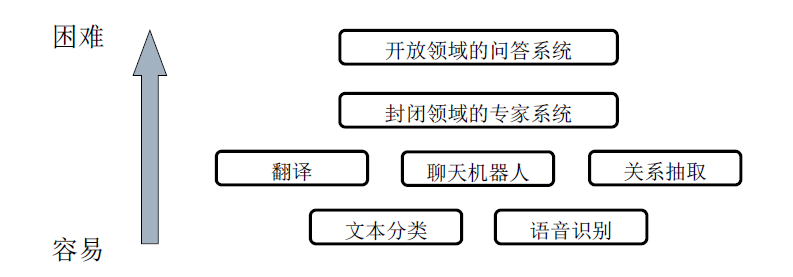
语言处理,可以包括语音识别、机器翻译、聊天系统、文本辅助和生成、语义理解、专家系统等。
语言识别是未来大多数人机交互、智能的基础,基于深度学习的语音识别已经能达到97%以上的准确率。语音识别目前的挑战主要来自于远场和噪声,在复杂噪声、人与声音采集设备距离相对较远的情况下,识别的效果急剧下降。
语音识别是未来人工智能应用一大核心支柱,即时翻译、人机交互、机器人等领域的人工智能应用都依赖于这项技术。
分类问题
人对事务认识的过程其实就是分类。
- 分类是人类对世界认知的基础,绝大多数的判断都是建立在分类基础上的,比如是好人还是坏人,是亲美还是反美等
- 实际应用中,推荐系统也是基于分类的,分类做得越细,推荐的效果就会越好
- 就逻辑编程来说,也仅信是无法通过简单的逻辑判断来识别对像
监督学习模型
机器学习是通过人为提取特征来处理:
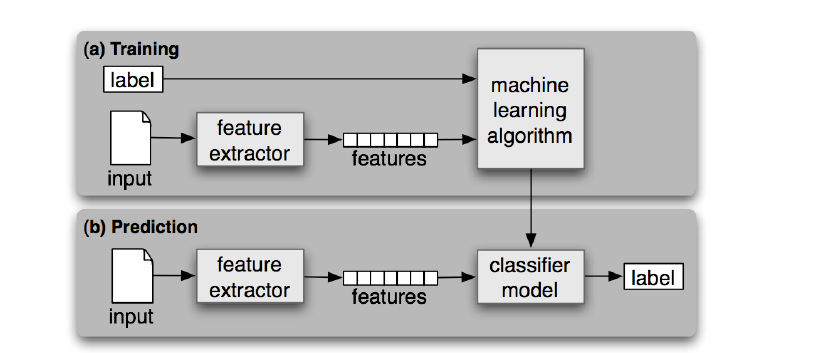
深度学习相比机器学习,先用大数据训练出模型,再通过模型预测,最大的特点是特征的提取是由神经网络通过海量的学习笔记来自动完成的。就像一个黑盒,end to end的模式。
文本到词
计算机是无法直接处理、读懂文本的语义,因此要对文本进行处理,必须把一篇非结构化的连续的文本,转换为一个数学问题,目前最常用的转换,就是找出文本的关键词,把关键词用一个数学特征来代替。
分词
分词最主要是针对中文的,因为以英文为代表的拉丁文语系,文本的单词之间是有天然分隔的,而中文则没有。
中文分词的手段主要依靠字典和统计学结合,分词是所有基于文本的应用的基础,分词效果直接决定了后续的使用;如果分词质量不高,后面的应用都会出错。
- 交集型歧义:从小/学/电脑,从/小学毕业
- 组合型歧义:一位/美军/中将/曾经/说过,新建/的/地铁/中/将/有3条线路
- 混合型歧义:人才能,人才/能,人/才能
分词本身就是一个人工智能在解决的问题,而分词的结果又是其它更高级的自然语言处理的基础,分词的质量直接影响后续的文本处理的能力。
停用词
停用词本身没有太明确的含义,但是它们大量出现,在文本分析处理的时候,会形成噪声,把有明确含义的词汇淹没,造成识别的困难,因此去掉停用词可以认为是一个去噪声的过程。
停用讯大致分为两类:
- 功能词,比如:吧、啊
- 词汇词,比如 不但、别说
文本的特征
统计每一篇文章里,各个词的词频,称为Term Frequency
对每一个词汇,统计它在各个文档里出现的频次,用总文件数/包含该词汇的文件的数量,再取对数,称为Inverse Document Frequency。
- IF-IDF
- Word of Bags
- Word Vector
获取海量的标记数据
任何机器学习以及我们现在提到的人工智能的方法,都是基于大数据的应用。根据人工智能解决核心方法:特征+标注数据+梯度下降训练,海量的高质量的标注数据是人工智能的最重要的部分,包括特征的提取往往也是基于海量数据来自动完成的,而从特征到结果的训练也需要海量的标注数据,所以获取数据往往是人工智能研究领域,最耗时、耗成本也是最有门槛的工作。
对于文本而言,获取数据可以依赖爬虫。互联网是一个开放的世界,所有存在的数据我们几乎都可以获取到,而获取数据以及对数据的利用就有很多的技巧:
比如文本分类,一般情况,我们的做法是大量抓取文本,然后人工标注。这里其实有很多的捷径,比如我们想标注跑车,可以直接到汽车之家这样的网站,针对性抓取跑车栏目下的文章,默认把它们都标记为豪华汽车,这样来进行训练。
尽管可以快速获得大量“标注”数据,但是里面依然带有很多的噪声tve多情况下,数据本身也是带有大量噪声的,比如网页的文本,是HTML格式的,我们需要从HTML里批量自动化提取出来我们需要的信息的部分,因些数据清洗也是非常大的一部分工作。
数据清洗除了对数据进行抽取,还包括对数据做进一步的校正,比如通过一些规则去掉特征不明显的样本,去掉错误标注的样本,自动化实现对样本的预分类处理。
搭建机器学习系统和调参
选定方案+抓数据+清洗+标注+训练+调参+调优
人工智能的未来
未来,人工智能会限代大量依赖经验和统计做出决策的行业,科技快速发展要求我们终生学习。
门诊医生
基于学习和工作的经验积累,通过对检查结果数据的分析,给出诊断结果,开出药方,这样的基于训练和数据分析的结论是比较符合能被人工智能颠覆的特征。
翻译
在可见的未来,简单的文本的语义翻译工作基本能被人工智能取代,意味着人类95%的翻译工作可能交给机器,只有5%的校准、优化可能由人来完成。
无人驾驶
按照目前的评估,10年左右,无人驾驶可以上路,最先被代替的行业,可能是固定线路的卡车司机。运行在高速公路上的卡车,所需要处理的情况最简单,人机的问题最少,有可能最早被无人驾驶取代。
快递
Amazon的无人机快递、京东的无人车快递都已经做了试运营,快递行业会被人工智能颠覆掉。
90%的岗位在未来会消失!但不要悲观,因为会出现大量新的工作岗位(不仅限于研究和开发)来支撑人工智能的发展。
根据个人所了解到的信息,对比视觉和语言处理,我更看好语言处理的前景,这里列出从事NLP需要的知识:
数学:线性代数、概率论、马尔可夫过程、贝叶斯方程、最小二乘、交叉熵
语言模型:N-GRAM、LDA、TF-IDF、词向量
机器学习:SVM、LR、决策树、KNN等
神经网络:RNN、LSTM、GRU等
方案:Seq2Seq、Attention、Beam Search、End to End
工程:爬虫,Python,Tensorflow
学术:读懂并实践至少10遍行业各个领域的经典论文