
冒泡排序
原理:
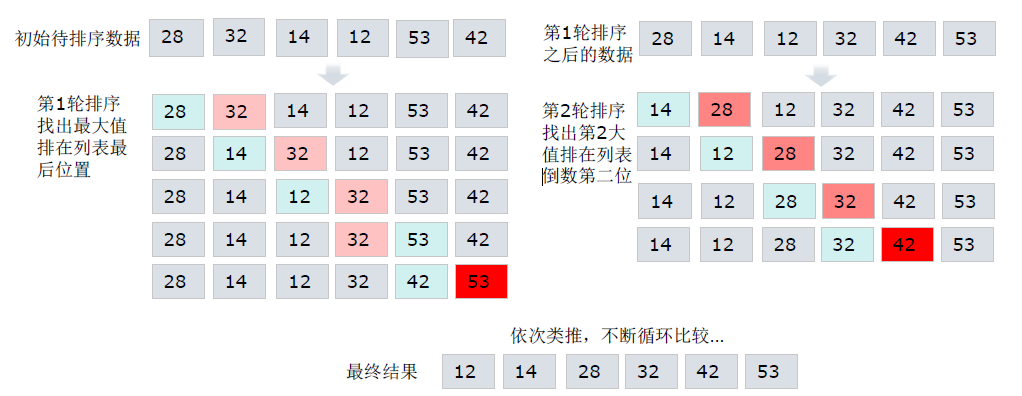
循环遍历列表,每次循环找出本次循环最大的元素排在后边
需要使用嵌套循环实现,外层循环控制总循环次数,内存循环负责的循环比较
算法:
第一轮循环5次 = 循环列表的长度6 - 1,即元素之间比较次数;找出最大元素
第二轮循环4次 = 循环列表的长度6 - 找出的最大值个数1 - 1;依次类推。
第n轮循环n次 = 循环列表长度 m - 找出的最大值个数 j - 1
n = 列表元素个数 - 1
实现:
# 排序的总轮数=列表元素个数 - 1
# 每轮元素互相比较的次数 = 列表元素个数 - 已经排好序的元素个数 - 1
#data_list:待排序列表
def bubble_sort(data_list):
num = len(data_list) #列表元素个数
for i in range(0,num -1):#排序的总轮数
print("第{}轮:".format(i))
for j in range(0,num-i-1):
if data_list[j] > data_list[j+1]:#前后两个元素比较
data_list[j],data_list[j+1] = data_list[j+1],data_list[j]
print(data_list)
选择排序
原理:
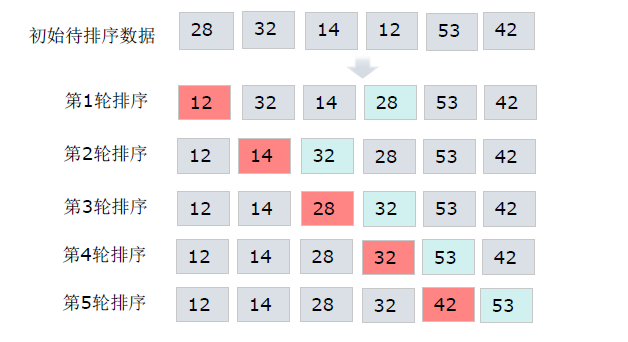
将待排序列表看成是已排序和未排序两部份
每次从未排序列表中找出最小值放到已排序列表未尾
算法:
在长度为n的无序数组中,第一次遍历n-1个数,找到最小的数值与第一个元素交换;
第二次遍历n-2个数,找到最小的数值与第二个元素交换;
......
第n-1次遍历,找到最小的数值与第n-1个元素交换,排序完成。
实现:
#data_list:待排序列表
def select_sort(data_list):
list_len = len(data_list) #待排序元素个数
for i in range(0,list_len-1):#控制排序比较总轮数
tmp_min_index = i
for j in range(i+1,list_len):
if data_list[tmp_min_index] > data_list[j]:
tmp_min_index = j
if i != tmp_min_index:
data_list[i],data_list[tmp_min_index] = data_list[tmp_min_index],data_list[i]
print(data_list)
快速排序
原理:
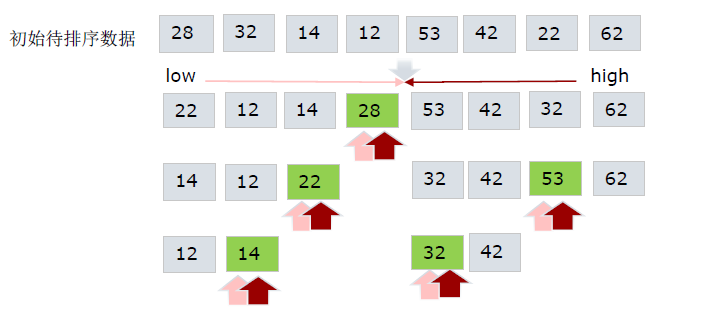
一次排序按照一个基准值将待排序的列表分割成两部份,基准值左边是比基准小的元素,基准值右边是比基准值大的元素
按照上一步的方法对基准值左右两部份数据分别进行快速排序
算法:
先从数列中取出一个数作为基准值;
将比这个数小的数全部放在它的左边,大于或等于它的数全部放在它的右边;
对左右两个小数列重复第二步,直至各区间只有1个数。
实现:
#快速排序
#data_list:待排序列表
def quick_sort(data_list,start,end):
#设置递归结束条件
if start >= end:
return
low_index = start#低位游标
high_index = end #高位游标
basic_data = data_list[start] #初始基准值
#低位游标不能超过高位游标,防止到重合的点继续游标移动
while low_index < high_index:
#模拟高位游标从右向左指向的元素与基准值进行比较,比基准值大则高位游标一直向左移动
while low_index < high_index and data_list[high_index] >= basic_data:
high_index -= 1
if low_index != high_index:
#当高位游标指向的元素小于基准值,则移动该值到低位游标指向的位置
data_list[low_index] = data_list[high_index]
low_index += 1 #低位游标向右移动一位
while low_index < high_index and data_list[low_index]<basic_data:
low_index +=1
if low_index != high_index:
data_list[high_index] = data_list[low_index]
high_index -= 1
data_list[low_index] = basic_data
#递归调用
quick_sort(data_list,start,low_index-1) #对基准值左边未排序队列排序
quick_sort(data_list,high_index+1,end) #对基准值右边未排序队列排序
list = [28,32,14,12,53,42]
quick_sort(list,0,len(list)-1)
print('---------排序结果--------------')
print(list)
归并排序
原理
先递归分解序列,再排序合并序列
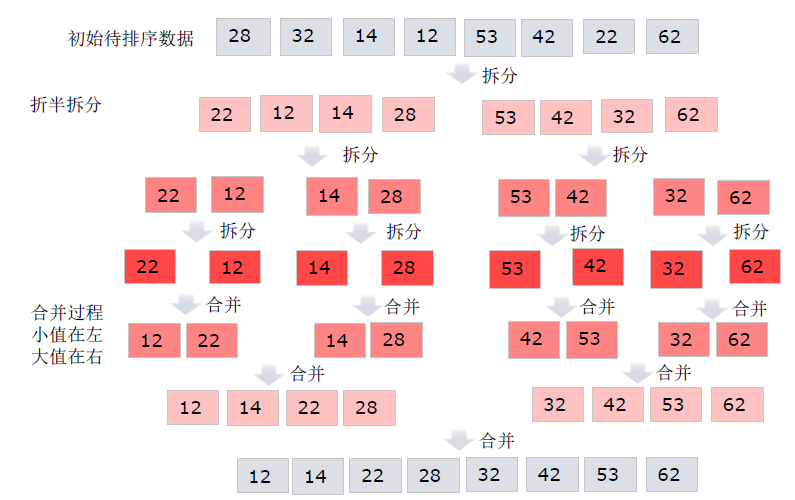
注意:图片第二行拆半拆分应该是:22 32 14 12 53 42 22 62的顺序,但是原理如图片所示
算法:
(1)拆分到不能分为止
(2)合并的过程中进行排序
实现:
#归并排序
#data_list:待排序列表
def merge_sort(data_list):
if len(data_list)<=1:
return data_list
#根据列表长度确定拆分的中间位置
mid_index = len(data_list) // 2
# left_list = data_list[:mid_index] #使用切片实现对列表的切分
# right_list = data_list[mid_index:]
left_list = merge_sort(data_list[:mid_index])
right_list = merge_sort(data_list[mid_index:])
return merge(left_list,right_list)
def merge(left_list,right_list):
l_index = 0
r_index = 0
merge_list = []
while l_index < len(left_list) and r_index < len(right_list):
if left_list[l_index] < right_list[r_index]:
merge_list.append(left_list[l_index])
l_index += 1
else:
merge_list.append(right_list[r_index])
r_index += 1
merge_list += left_list[l_index:]
merge_list += right_list[r_index:]
return merge_list
list = [28,32,14,12,53,42]
new_list = merge_sort(list)
print('---------排序结果--------------')
print(new_list)